Incident management a Problem management
Incident management se soustředí na obnovení neočekávaně přerušených či zhoršených služeb v co nejkratším čase s cílem minimalizovat dopad na business. Problem management se soustředí na analýzu příčiny incidentů s cílem eliminovat budoucí incidenty.
Níže uvedený text obsahuje základní principy řešení těchto procesů v ObjectGears, tak jak reflektují best practise ITIL v3 - Service Operation.
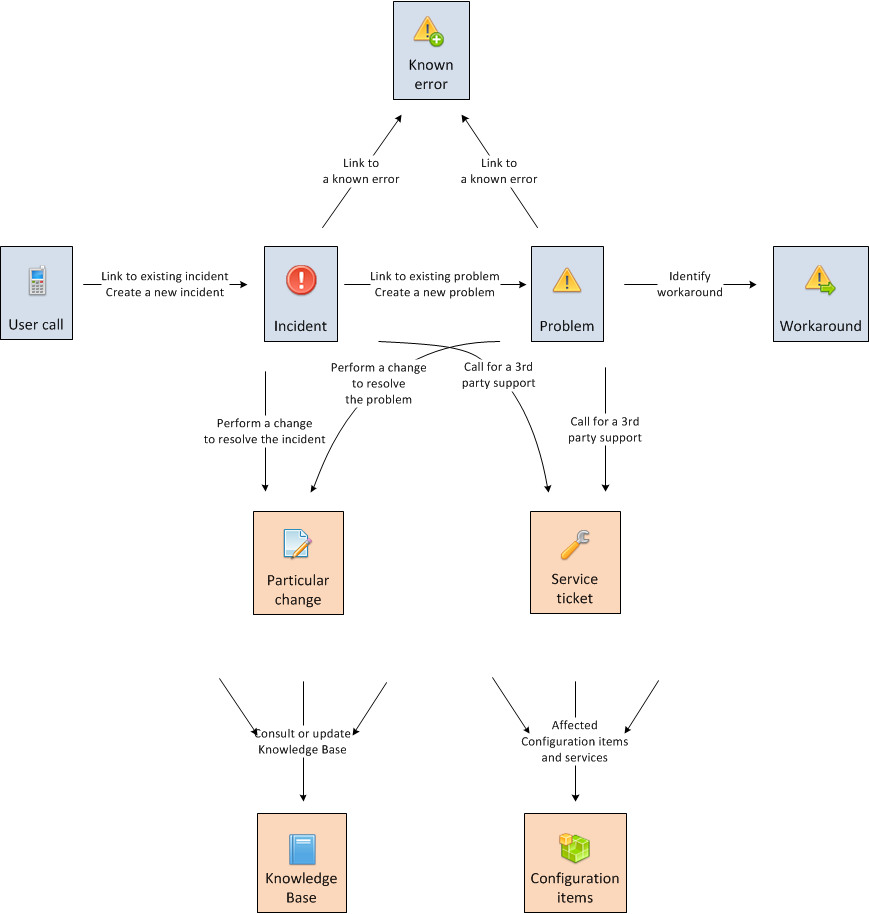
Základní entitou procesů Incident a Problem management je entita Incident, která představuje situaci přerušení či zhoršení služby. Incident je zakládán ve chvíli, kdy je taková situace identifikována.
Dopad, urgentnost, priorita a cílový čas řešení
Mezi základní atributy Incidentu patří jeho Dopad a Urgentnost. Dopad představuje míru postižení business - z pohledu počtu uživatelů či zákazníků (od jednotlivců, přes skupinu po velké množství), finančních ztrát nebo reputace organizace. Při implementaci procesu jsou jednotlivé úrovně dopadu popsány z pohledu dané organizace. Urgentnost představuje míru potřeby situaci řešit z pohledu tendence incidentu narůstat na vážnosti (při neřešení hrozí rozšíření dopadu), neměnit rozsah dopadu či naopak tendence samovolného odeznívání dopadu. Je sestavena matice priorit, která pro jednotlivé kombinace dopadu a urgentnosti stanoví Prioritu.
| Dopad | Urgentnost | Priorita |
| Vysoký | Vysoká | 1 - Kritická |
| Vysoký | Střední | 2 - Vysoká |
| Vysoký | Nízká | 3 - Střední |
| Střední | Vysoká | 2 - Vysoká |
| Střední | Střední | 3 - Střední |
| Střední | Nízká | 4 - Nízká |
| Nízký | Vysoká | 3 - Střední |
| Nízký | Střední | 4 - Nízká |
| Nízký | Nízká | 5 -Vemi nízká |
Každé prioritě odpovídá Cílový čas odezvy a Cílový čas vyřešení incidentu. U kritického incidentu je tak např. stanovena povinnost okamžitého potvrzení převzetí incidentu do řešení a cílový čas vyřešení 1 hodina.
Příklad Priorit:
| Kód | Název | Odezva | Vyřešení |
| 1 | Kritická | Okamžitě | 1 hodina |
| 2 | Vysoká | 10 minut | 4 hodiny |
| 3 | Střední | 1 hodina | 8 hodin |
| 4 | Nízká | 4 hodiny | 24 hodin |
| 5 | Velmi nízká | 1 den | 1 týden |
Každý incident je při svém vzniku klasifikován z pohledu dopadu a urgentnosti a na základě těchto hodnot je určena jeho priorita. Podle služby, která je incidentem dotčena, a maximálního času na řešení je určen cílový čas řešení.
Příklad: Pokud je služba garantována pouze od 8:00 do 17:00 a v 16:00 je identifikován incident s prioritou a časem na vyřešení 8 hodin, cílový čas vyřešení je určen jako následující den v 15:00. Tento čas zohlední závažnost incidentu a potřebu dostupnosti služby a stanoví odpovídající cílový čas. Méně závažný incident tak má nastaven odpovídající cílový čas a pro jeho vyřešení nejsou pracovníci nuceni pracovat v mimořádných směnách.
Kategorizace incidentu
Incident je kategorizován pro určení řešitelské skupiny a následný reporting - identifikace oblastí, ve kterých dochází k incidentům.
Založení incidentu a vazby na další entity a procesy
Incident může být založen třemi základními způsoby:
- Založení incidentu pracovníkem IT
- Založení incidentu pracovníkem IT při řešení Hlášení uživatele. Pracovník IT Service Desk identifikuje, že se jedná o incident. (ObjectGears umožňuje rychlé vytvoření incidentu z Hlášení uživatele a jeho připojení pomocí tlačítka dostupného v záznamu Hlášení uživatele.)
- Automatické založení monitorovacím systémem, který vyhodnotí určitou situaci (např. nedostupnost služby, serveru atd.)
Známá chyba
Při řešení incidentu může být zjištěno, že příčinou je Známá chyba. IT udržuje v ObjectGears evidenci známých chyb. Navázání incidentu na známou chybu umožňuje následně stanovit dopad známých chyb na business, počet s nimi spojených incidentů, úspěšnost jejich řešení atd.
Problém
Při řešení Incidentu může řešitel identifikovat, že příčinou incidentu je známý Problém. Navázání Incidentu na Problém umožňuje stanovit dopad konkrétního nevyřešeného problému ma business, počet s ním spojených incidentů, výpadků atd. V případě, že řešitel identifikuje příčinu incidentu a související problém není dosud založen, ObjectGears umožňuje rychlé vytvoření Problému z Incidentu a jeho připojení pomocí tlačítka dostupného v záznamu Incidentu.)
I problém může být navázán na záznam Známé chyby.
Workaround
Protože cílem řešení Problému je odstranit příčinu, jeho čas očekávaného vyřešení je z podstaty věci řádově delší než v případě incidentu. Při řešení problému někdy řešitel identifikuje Workaround - způsob dočasného řešení, které obchází příčinu problému. V takovém případě je třeba problém na Workaround napojit. Pokud později dojde k výskytu incidentu, u něhož je identifikována souvislost s daným problémem, řešitel má možnost Incident vyřešit dle postupu ve Workaroundu.
Změna
Pokud je při řešení Incidentu nebo Problému zjištěna potřeba Změny (viz Change management), je tato zaevidována a Incident či Problém k ní napojen. To umožní zpětně dohledat, které Změny byly učiněny kvůli řešení určitého Incidentu nebo Problému.
Funkční a hierarchická eskalace
V případě, že je zřejmé, že incident nemůže být vyřešen pracovníky Service desku, dochází k funkční eskalaci - incident je předán na řešitele druhé úrovně (zvláštní tým dle oblasti, které se incident týká - např. Servery, DB Administrátoři...). Podobně může být řešení Incidentu či Problému eskalováno na třetí úroveň podpory - dodavatele. V této souvislosti dochází k založení Servisního požadavku na základě smlouvy, která je s dodavatelem uzavřena. Protože ObjectGears umožňuje efektivní propojení jednotlivých entit, je možné v detailu incidentu vidět i vazby na Servisní požadavky. Řešitel, manažer nebo jiný pracovník tak může vidět komplexní obraz řešení daného incidentu nebo problému včetně provedených Změn či prací dodavatelů, na které byl Incident či Problém eskalován.
K hierarchická eskalaci dochází, pokud je zřejmé, že incident nebyl/nebude vyřešen včas, je třeba přidělit dodatečné zdroje na řešení daného incidentu nebo naplánovat mimořádné kroky. V rámci hierarchické eskalace jsou informováni příslušní IT manažeři.
Znalostní báze
Poznatky z řešení Incidentů a Problémů by měly být reflektovány ve Znalostní bázi a vytvořené či aktualizované články navázány k příslušným Konfiguračním položkám.
Konfigurační položky
K Incidentům, Problémům, Změnám a dalším entitám použitým v procesu Incident a Problem management je třeba navázat Konfigurační položky, kterých se týkají. ObjectGears pak umožňuje při zobrazení daných konfiguračních položek zobrazit Incidenty, Problémy, Změny a další entity, které na ně byly navázány. To opět uživateli poskytuje komplexní obraz dané Konfigurační položky.
Reporting
Fungování procesu je třeba vyhodnocovat a sledovat, zda naplňuje očekávání (např. dodržení lhůt na řešení incidentů), jak si stojí jednotliví řešitelé (např. počty uzavřených incidentů, počty přidělených incidentů po termínu) či ve kterých oblastech je nejvíce incidentů a zasluhují tedy největší pozornost. K tomu slouží předdefinované reporty, které lze dále upravovat a rozšiřovat.
Příklady obrazovek
Detail Incidentu
Základními vlastnostmi incidentu jsou název, kód, popis, datum a čas vzniku, jeho status, zákazník, řešitel, dopad na business a urgentnost, z nichž se vypočítává priorita (a doba na řešení incidentu) a cílový čas vyřešení incidentu. Ve spodní části obrazovky vidíme záložky se souvisejícími změnami, které byly učiněny v rámci řešení incidentu, servisní požadavky na partnery (eskalace incidentu na firmy poskytující 3rd level support), uživatelská hlášení, která souvisí s incidentem a historie řešení incidentu (reporting času stráveného na řešení incidentu jednotlivými pracovníky). Zcela dole vidíme tlačítko NOVÝ PROBLÉM, které založí záznam problému s daty obsaženými v incidentu a incident, k němu napojí, v případě, že řešitel identifikuje obecnou příčinu incidentu, která dále přetrvává, i když byl incident vyřešen a služba obnovena.
Detail incidentu 2
K incidentu je možné nalinkovat další entity. Známou chybu (identifikovanou chybu, která se v systému vyskytuje a je uznána výrobcem systému jako chyba - typicky dodavatel systému stanovuje verzi/patch, které danou chybu řeší), Problém (obecná příčina přetrvávající i po vyřešení incidentu a obnovení služby) nebo související Konfigurační položky, kterých se incident týká.
.
Detail Problému
V rámci problému evidujeme podobné skutečnosti jako u incidentu. Můžeme odkázat na Známou chybu nebo na Workaround, který umožňuje vyhnout se projevům problému. V spodní části obrazovky vidíme související incidenty (frekvence výskytů projevu problému), servisní požadavky (eskalace na partnery zajišťující 3rd level support) a související změny učiněné v rámci řešení problému a historii řešení problému.
Detail Známé chyby
U známé chyby evidujeme název, kód a popis. Ve spodní části obrazovky vidíme přehled incidentů a problémů, které známou chybu identifikovali jako příčinu.
Detail Servisního požadavku
V rámci servisního požadavku sledujeme průběh řešení úkolu zadaného servisnímu partnerovi. Máme možnost evidovat servisní smlouvu, na základě které byl servisní požadavek zadán, ID úkolu v systému externího partnera a odkaz na incident, problém či úkol, kterého se týká.
Dashboard s reporty pro Incident a Problem management
Část obrazovky dashboardu s reporty pro vyhodnocení procesu Incident a Problem management. Nově vytvořené reporty lze do dashboardu vložit. Podobně je možné vytvořit další dashboardy specializované na konkrétní specifické reporty a vzájemně je propojit.
Maximalizace reportu z Dashboardu
Na dashboardu je zobrazeno několik reportů. Ty je možné maximalizovat klepnutím na ikonu v jejich pravém horním rohu. Report je pak krásně vidět přes celou obrazovku. Podobně je možné maximalizovaný report zavřít a vrátit se na celkový dashboard.
Založení incidentu a problému v1.7.1.0
Incident a Problem management. Ukázka založení Incidentu z portálu Service Desku a založení Problému z Incidentu s přenosem dat z incidentu a návratem do Incidentu poté, co byl Problém vytvořen. Přehled souvisejících Incidentů a Problémů se zobrazuje i v detailu Konfigurační položky.